The Evolution of Data Access in Web3

The Importance of Data in Blockchains
Data is crucial in blockchain technology, serving as the foundation for developing decentralized applications (dApps). While much of the current conversation revolves around data availability (DA) — ensuring that recent transaction data is accessible to every network participant for verification — there is another equally important aspect that often goes overlooked: data accessibility.
In the era of modular blockchains, DA solutions have become indispensable. These solutions ensure that transaction data is available to all participants, allowing for real-time verification and maintaining the integrity of the network. However, DA layers function more like billboards than databases. This means that data isn’t stored indefinitely; it gets removed over time, similar to how posters on billboards are eventually replaced with new ones.
On the other hand, data accessibility focuses on the ability to retrieve historical data, which is essential for the development of dApps and conducting blockchain analysis. This aspect is crucial for tasks that require access to past data to ensure accurate representation and execution. Despite its importance, data accessibility is less frequently discussed but is just as vital as data availability. Both serve different but complementary roles in the blockchain ecosystem, and a comprehensive approach to data management must address both to support robust and efficient blockchain applications.
How Blockchain Data Was Previously Retrieved
Since their inception, blockchains have revolutionized infrastructure and enabled the creation of decentralized applications (dApps) across various fields like gaming, finance, and social networking. However, building these dApps requires accessing large amounts of blockchain data, which can be both challenging and costly.
One option for dApp developers is to host and run their own archival RPC nodes. These nodes store all historical blockchain data from the very beginning, allowing full data access. However, maintaining an archival node is expensive and has limited query ability, making it not possible to query data in a format that developers need. While running less expensive nodes is an option, these nodes have limited data retrieval capabilities, which can hinder the operation of a dApp.
Another approach is to use commercial RPC (Remote Procedure Call) node providers. These providers handle the costs and management of the nodes, supplying data through RPC endpoints. Public RPC endpoints are free but have rate limits that can negatively impact the user experience of a dApp. Private RPC endpoints offer better performance by reducing congestion, but they involve a lot of back-and-forth communication for even simple data retrieval. This makes them request-heavy and inefficient for complex data queries. Additionally, private RPC endpoints often struggle with scalability and lack compatibility across different networks.
A Superior Alternative: Blockchain Indexers
Blockchain indexers play a crucial role in organizing on-chain data and sending it to a database for easy querying, which is why they are often referred to as the “Google of blockchains.”. They work by indexing blockchain data and making it readily available through a query language similar to SQL, using APIs such as GraphQL. By providing a unified interface for querying data, indexers allow developers to use standardized query languages to retrieve the information they need quickly and accurately, significantly simplifying the process.
Different types of indexers optimize data retrieval in various ways:
- Full Node Indexers: These indexers run a full blockchain node and extract data directly from it, ensuring complete and accurate data but requiring significant storage and processing power.
- Lightweight Indexers: These indexers rely on full nodes to fetch specific data as needed, reducing storage requirements but potentially increasing query time.
- Dedicated Indexers: Specialized for certain types of data or specific blockchains, these indexers optimize retrieval for particular use cases, such as NFT data or DeFi transactions.
- Aggregating Indexers: These indexers pull data from multiple blockchains and sources, including off-chain information, providing a unified query interface, which is especially useful for multi-chain dApps.
Ethereum alone requires 3TB of storage with an Erigon archive node with growing data storage as chains grow over time. Indexer protocols deploy multiple indexers, enabling efficient indexing and querying of large volumes of data at high speeds — something RPCs cannot achieve.
Indexers also allow for complex queries, easy filtering of data based on different criteria and data to be analyzed after being extracted. Some indexers also allow aggregation of data from multiple sources, which prevents having to deploy multiple APIs in a multi-chain dApp. By distributing across multiple nodes, indexers provide enhanced security and performance compared to RPC providers who may experience outages and downtime due to their centralized nature.
Overall, indexers enhance the efficiency and reliability of data retrieval compared to RPC node providers, while also reducing costs associated with deploying individual nodes. This makes blockchain indexer protocols the preferred choice for dApp developers.
Indexer Use Cases
As mentioned earlier, building dApps require the retrieval and reading of blockchain data to run their service. This includes any type of dApp, including DeFi, NFT platforms, gaming and even social networks since these platforms require data to be read before they can execute other transactions.
DeFi
DeFi protocols require different information before they can quote their users' specific prices, ratios, fees and more. Automated Market Makers (AMM) require price and liquidity information about certain pools to calculate swap rates while lending protocols require utilization ratios to determine lending/borrowing rates and debt ratios for liquidation. Feeding information into their dApp is essential before they calculate rates for users to execute upon.
Gaming
GameFi requires fast indexing and access to data to ensure smooth gameplay for users. It is only with lightning fast retrieval of data and execution can Web3 games compare to their Web2 counterparts in performance to attract more users. These games require data such as land ownership, in-game token balance, in-game actions and more. Using indexers, they can better ensure steady data flow and steady up-time to ensure a flawless gameplay experience.
NFT
NFT marketplaces and lending platforms require indexed data access to a variety of information such as NFT metadata, ownership and transfer data, royalties information and more. Fast indexing of such data prevents having to go through each NFT individually to look for ownership or NFT attributes data.
Be it a DeFi Automated Market Maker (AMM) that requires price and liquidity information or a SocialFi application that requires updates about new users’ posts, being able to retrieve data quickly is essential to enable dApps to function well. With indexers, they provide efficient and correct retrieval of data to give a smooth user experience.
Analytics
Indexers provide a means to extract specific data from raw blockchain data, including smart contract events in each block. This opens up the opportunity for more specific data analysis to provide comprehensive insights.
For example, perpetual trading protocols may find out which tokens have high trading volumes that are generating fees on leading DEXes to decide whether to list these tokens as perpetual contracts on their platform. DEX developers can create dashboards for their own products, giving insight into which pools have the highest return or deepest liquidity. Public dashboards can also be created, giving developers the freedom and flexibility to query any type of data to be illustrated on a graph.
Since there are multiple blockchain indexers available, identifying the differences between indexing protocols is crucial to ensure developers opt for an indexer that best suits their needs.
Overview of Blockchain Indexers
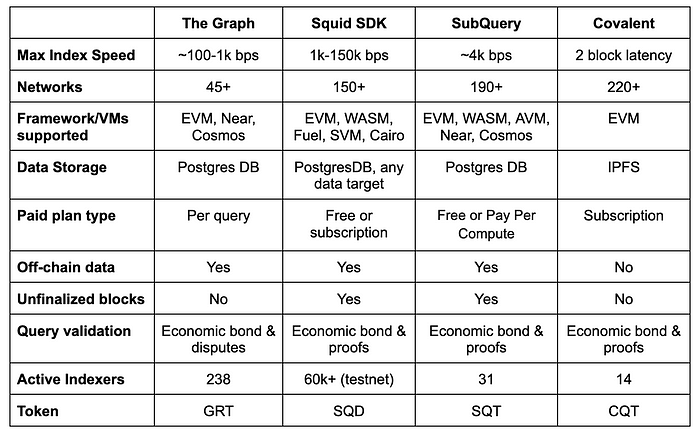
A Look at Indexers
The Graph
The Graph was the first indexer protocol that first launched on Ethereum which enabled easy querying of transaction data that was previously not easily accessible. Using subgraphs, it defines and filters a subset of data that is collected from the blockchain, such as all transactions associated with the Uniswap v3 USDC/ETH pool.
Using Proof of Indexing, Indexers stake the native token GRT for indexing and querying services, which delegators can choose to stake their tokens with. Curators access subgraphs of high quality, to help indexers identify which subgraphs to index data for to earn the best query fees. In its transition towards greater decentralization, The Graph will eventually discontinue its hosted service and require subgraphs to upgrade onto its network while providing an upgrade indexer.
Its infrastructure enables an average cost-per-query of $40 per million queries, which costs significantly less than self hosting nodes. Using File Data Sources, it also supports parallel indexing of both on-chain and off-chain data at the same time for efficient data retrieval.
Looking at The Graph’s indexer rewards, it has been growing steadily over the past few quarters. This is partially due to the increase in queries, but also attributed to the growth in token price due to their plans to integrate AI-assisted querying in the future.
Subsquid
Subsquid is a peer-to-peer, horizontally scalable decentralized data lake that efficiently aggregates large amounts of both on-chain and off-chain data, secured with zk-proofs. A decentralized network of workers, each node is responsible for storing data from a specific subset of blocks, hastening the data retrieval process by quickly identifying the nodes holding the required data.
Subsquid also supports real-time indexing, allowing blocks to be indexed before they are finalized. It also enables the storage of data in developers’ chosen formats, facilitating easier analytics using tools such as BigQuery, Parquet, or CSVs. Additionally, subgraphs can be deployed on the Subsquid Network without migrating to the Squid SDK, enabling code-free deployment.
While still in the testnet phase, Subsquid has achieved impressive stats, with over 80,000 testnet users, more than 60,000 squid indexers deployed, and over 20,000 verified developers on the network. Very recently, on June 3rd, Subsquid launched the mainnet of their data lake.
In addition to the indexing, the Subsquid Network data lake is intended as a replacement for RPCs in such use cases as analytics, ZK/TEE co-processors, AI agents, and oracles.
SubQuery
SubQuery is a decentralized middleware infrastructure network that provides both RPC and indexed data services. Initially supporting Polkadot and Substrate networks, it has now expanded to include over 200 chains. It works similarly to The Graph using Proof of Indexing, with indexers that index data and provide query requests, and delegators who stake to indexers. However, instead of curators, it introduces consumers who submit purchase orders to signal guaranteed revenue for indexers.
It will introduce the SubQuery Data Node which supports sharding to prevent constant syncing of new data between every node, thus optimizing query efficiency while moving towards greater decentralization. Users can choose to pay per compute of about 1 SQT token per 1000 requests, or set up custom fees for indexers through agreements.
Although SubQuery only launched their token earlier this year, emission rewards for both nodes and delegators have been increasing QoQ in USD value as well which represents an increasing amount of querying services provided on their platform as well. The total amount of SQT staked has increased from 6M to 125M since TGE, highlighting the growth in participation of their network.
Covalent
Covalent is a decentralized indexer network that creates a replica of blockchain data by Block Specimen Producers (BSPs) network nodes through a bulk export method and publishes a proof on the Covalent L1 blockchain. These data are then refined by Block Result Producer (BRP) nodes to filter out data based on set rules.
Through its unified API, developers can easily pull relevant blockchain data in a consistent request and response format that removes the need from having to write custom complex queries to access data. These pre-configured datasets can be pulled from network operators using CQT tokens as means of payment that are settled on Moonbeam.
Covalent’s rewards seem to be in an overall growing trend from Q1 23 to Q1 24, partially attributed to the increase in price for Covalent’s token CQT.
Considerations in Choosing an Indexer
Customizability of Data
Some indexers such as Covalent are general-purpose indexers that only provide standard pre-configured datasets through an API. Although they might be fast, they do not offer flexibility for developers that require customized datasets. By using indexer frameworks, it allows for more custom data handling to provide for application-specific needs.
Security
Indexed data has to be secure, or the dApps built on these indexers are prone to attacks as well. For example, if transaction and wallet balance can be manipulated, dApps are at risk of being drained of liquidity which affect their users. Although all indexers employ some form of security through the staking of tokens by indexers, other indexer solutions may employ the use of proofs for further security.
Subsquid provides the option for the use of optimistic and zk-proof while Covalent also publishes a proof that contains the hash of the block. The Graph provides dispute challenge periods against the indexer’s queries in an optimistic challenge window period style, while SubQuery generates Merkle Mountain proofs of each block to calculate a hash for every block of all data stored in their database.
Speed and Scalability
As blockchains grow over time, more transactions are added which makes indexing larger amounts of data more tedious since more processing power and storage is required. Maintaining efficiency as blockchain networks grow becomes more difficult, but indexer protocols introduce solutions to cater to these increasing requirements.
For example, Subsquid allows for horizontal scalability through the addition of more nodes for data storage, offering the ability to scale along with hardware improvements. The Graph offers parallelized streaming data to sync data faster, while SubQuery introduces node sharding to hasten the syncing process.
Networks Supported
Although the majority of blockchain activity still lies within Ethereum, different blockchains are gaining more popularity over time. For example, Layer 2s, Solana, Move blockchains, and Bitcoin ecosystem chains have their own set of growing developers and activity which will require indexing services as well.
Providing support to certain chains that are not supported by other indexer protocols can capture more market share fees. Indexing data-heavy networks such as Solana is no easy task, and only Subsquid has managed to provide indexing support for them so far.
Conclusion
Despite the widespread adoption of indexers for dApp development, the potential for indexers remains vast, particularly with the integration of AI. As AI continues to proliferate in both Web2 and Web3, its ability to improve hinges on accessing relevant data to train models and develop AI agents. Ensuring data integrity is crucial for AI applications, as it prevents models from being fed biased or inaccurate information.
In the realm of indexer solutions, Subsquid has shown significant progress with its performance and user metrics. Users have already begun experimenting with Subsquid to build AI agents, showcasing the platform’s versatility and potential in the evolving landscape of data indexing. Additionally, tools such as AutoAgora facilitate indexers in offering dynamic pricing for query services on The Graph using AI, while SubQuery supports multiple AI networks like OriginTrail and Oraichain for transparent data indexing.
The integration of AI with indexers holds promise for enhancing data accessibility and usability in blockchain ecosystems. By leveraging AI technologies, indexers can provide more efficient and accurate data retrieval, enabling developers to build more sophisticated dApps and analytics tools. As AI and indexers continue to evolve together, we remain optimistic about the future of data indexing and its role in shaping the decentralized digital landscape.
About DFG
Digital Finance Group (DFG) is a global blockchain and cryptocurrency investment firm founded in 2015 with assets under management of over $1 billion through a wide range of sectors within the blockchain ecosystem such as Web 3.0, CeFi, DeFi, NFTs, and the Polkadot ecosystem.
Investments include Circle, Ledger, Coinlist, FV Bank, Astar, ChainSafe, and over 150 more. DFG intends to create value, through analytical research, based on the most impactful and promising global blockchain and Web 3.0 projects that will bring a paradigm shift to the world.
DFG Website: https://dfg.group
DFG Twitter: @DFG__Official
DFG LinkedIn: DFG
