The Intersection of AI & DePIN

Introduction
AI and DePIN have both been hot trending narratives in Web3 since 2023, with AI at a 30 billion market cap and DePIN at 23 billion currently. These 2 categories are vast and extensive, each covering a wide spectrum of different protocols serving different areas and needs that should be covered individually. However, this piece aims to cover the intersection between the two, looking at the developments of protocols in this space.
In the AI tech stack, DePIN networks provide utility to AI through computing resources. The GPU shortage caused by the development of large tech companies has caused other developers who are building their own AI models to lack sufficient GPUs for compute. This often leads to developers opting for centralized cloud providers but causes inefficiencies from having to sign inflexible long-term contracts for high-performance hardware.
DePIN essentially provides a much more flexible and cost-efficient alternative by using token rewards to incentivize resource contribution that meets the network’s objective. DePIN in AI crowdsources GPU resources together from individual owners to data centers, forming a unified supply for users who require access to hardware. These DePIN networks not only offer customizability and on-demand access to developers requiring compute power, but also offer additional income to GPU owners who may be struggling to be profitable from being idle.
With so many AI DePIN networks in the market, it may be difficult to identify the differences between them and find the right network one might need. In the next part, we will explore what each protocol does and what they are trying to achieve, with some specific highlights that they have accomplished.
AI DePIN Network Overview
Each project mentioned here serves a similar purpose — a GPU compute marketplace network. The aim of this portion of the article is to examine the highlights of each project, what market focus they have, and any highlights that they have achieved. By first understanding their key infrastructure and offerings, can we then dig deeper to understand how they differ from each other which will be covered in the following section.
Render is the pioneer of P2P networks offering GPU computing power that previously focused on rendering graphics for content creation before expanding their scope to include AI compute tasks ranging from Neural Reflectance Field (NeRF) to generative AI by integrating toolsets such as Stable Diffusion.
What’s interesting:
- Founded by OTOY, a cloud graphics company with academy award winning technology
- GPU networks have been used by big players in the entertainment industry such as Paramount Pictures, PUBG, Star Trek, and more
- Partnered with Stability AI and Endeavor, integrating their AI models with 3D content rendering workflows using Render’s GPUs
- Approved multiple compute clients, integrating more DePIN networks’ GPUs
Akash dubs itself as the ‘Airbnb for hosting’, positioning itself as a “Supercloud” alternative to traditional platforms like AWS that support storage, GPU, and CPU compute. Leveraging developer-friendly tools like its Akash Container Platform and Kubernetes-managed computation nodes, it enables seamless software deployment across environments to be able to run any cloud-native application.
What’s interesting:
- Targets a broad range of computing tasks from general purpose computing to web hosting
- AkashML allows its network of GPUs to run over 15,000 models on Hugging Face while integrated with Hugging Face
- Notable applications are hosted on Akash, such as Mistral AI’s LLM model chatbot, Stability AI’s SDXL text-to-image model, and Thumper AI’s new foundational model AT-1
- Platforms building metaverses, AI deployment, and federated learning are utilizing Supercloud
io.net provides access to distributed cloud clusters of GPUs specifically focusing on AI and ML use cases. It aggregates GPUs from areas such as data centers, crypto miners, and other decentralized networks. Previously a quant trading company, it pivoted into its current business after it encountered significantly high prices for high-performance GPUs.
What’s interesting:
- Its IO-SDK is compatible to frameworks like PyTorch and Tensorflow and its multi-layered architecture that dynamically scales automatically to computational demands
- Supports the creation of 3 different types of clusters that can be spun up in under 2 minutes
- Strong partnership efforts to onboard other DePIN networks’ GPUs, including Render, Filecoin, Aethir, and Exabits
Gensyn serves GPU compute power focused specifically on machine learning and deep learning computations. It boasts to achieve more efficient verification mechanisms compared to existing methods using a combination of concepts such as Proof-of-Learning for verification of work, a Graph-based pinpoint protocol for re-running of verification work, and a Truebit style incentive game involving staking and slashing of compute providers.
What’s interesting:
- Projected its approximate hourly cost of a V100-equivalent GPU to be $0.40/h, enabling significant cost savings
- Through proof stacking, it enables pre-trained base models (foundation models) to be fine tuned for more specific tasks
- These foundation models will be decentralized and globally owned, offering additional capability beyond just a hardware compute network
Aethir exclusively onboards enterprise GPUs to focus on compute intensive sectors mainly in AI, Machine Learning (ML), Cloud Gaming, and more. Their Containers in the network act as virtual endpoints for the execution of cloud-based applications, shifting workloads from local devices to the container for a low latency experience. To ensure quality services for their users, they adjust resources by moving GPUs closer to data sources based on the demand and location.
What’s interesting:
- Apart from AI and cloud gaming, Aethir also expands to cloud phone services and has partnered with APhone to bring decentralized cloud smartphones
- Boasts a wide range of partnerships with large Web2 companies including NVIDIA, Super Micro, HPE, Foxconn, and Well Link
- Multiple partnerships in Web3 such as CARV, Magic Eden, Sequence, Impossible Finance, and more
Phala Network acts as an execution layer for Web3 AI solutions. Its blockchain serves as a trustless cloud computing solution that handles privacy issues through the use of its Trusted Execution Environment (TEE) design. Instead of serving as a compute layer for AI models, its execution layer enables AI agents to be controlled by smart contracts on-chain.
What’s interesting:
- Acts as a coprocessor protocol for verifiable compute but also enables AI agents to on-chain resources
- Its AI agent contracts can access top LLMs such as OpenAI, Llama, Claude, and Hugging Face through Redpill
- Include multi-proof systems such as zk-proofs, Multi Party Computation (MPC), and Fully Homomorphic Encryption (FHE) in the future
- Support other TEE GPUs such as H100 in the future, enabling computing capabilities
Comparing Projects

Importance
The Availability of Clusters and Parallel Compute
Distributed computing frameworks enabled the clustering of GPUs, providing more efficient training without compromising on model accuracy with enhanced scalability. Training of more complex AI models requires large computational power, which will often have to rely on distributed computing to meet its needs. To put things in perspective, OpenAI’s GPT-4 model which had over 1.8 trillion parameters was trained using ~25,000 Nvidia A100 GPUs in 128 clusters over 3–4 months.
Previously, Render and Akash only served single-purpose GPUs which could have limited their market demand for GPUs. However, most projects highlighted have now incorporated clusters to provide for parallel computations. Io.net’s partnerships with other projects like Render, Filecoin, and Aethir to onboard more GPUs into its network have managed to deploy over 3,800 clusters in Q1 24. Even though Render does not support clustering, it works similarly to it by breaking up individual frames for multiple different nodes to process different ranges of frames simultaneously. Phala currently only supports CPUs, but enables CPU workers to be clustered.
Incorporating clustering frameworks into their networks for AI workflows is important, but the number and type of GPUs available for clustering that is required to meet the needs of AI developers is a separate issue which we will take a look at in the later part.
Data Privacy
Developing AI models requires the use of extensive datasets, which may come from a variety of sources in different forms. Sensitive datasets such as personal medical records, user financial data and more may be at risk of being exposed to model providers. Samsung’s internal ban for ChatGPT due to privacy concerns from sensitive code being uploaded to the platform and Microsoft’s data exposure accident involving 38TB of private data further highlights the importance of having sufficient security measures in place when using AI. Having various methods for data privacy is thus crucial to give control of data back to the data provider.
Most projects covered use some form of data encryption for data privacy. Data encryption ensures that the transfer of data in the network from the data provider to the model provider (data recipient) is protected. Render utilizes encryption and hashing of render results when they are posted back onto the network while io.net and Gensyn employ some form of data encryption. Akash uses mTLS authentications, allowing only selected providers by the tenants to receive the data.
Io.net however has recently partnered with Mind Network to introduce Fully Homomorphic Encryption (FHE), to allow encrypted data for processing without having to decrypt it first. By enabling data to be securely transferred for training purposes without revealing the identity and data contents, this innovation can better ensure data privacy over existing encryption techniques.
Phala Network introduces TEE, which is a secure area in the main processor of connected devices. Through this isolation mechanism, it prevents access or modification of data from external processes regardless of privilege level even from individuals with physical access to the machines. On top of TEE, it combines the use of zk-proofs as well in its zkDCAP verifier and jtee command line interface for programs integrating with RiscZero zkVM.
Compute Completion Proof and Quality Checks
These projects offer GPUs that offer compute power for a range of services. Since these services can range from rendering graphics to AI compute, the end quality of such tasks may not necessarily always be up to the users’ standard. A form of completion proof can be utilized to represent that the particular GPU rented by the user was actually used to run the service required, and quality checks are beneficial for the user requesting such work to be done.
Upon compute completion, both Gensyn and Aethir generate a proof to signify the completed work while io.net’s proof represents the rented GPU’s power was fully used without foul play. Quality checks for completed compute are present in both Gensyn and Aethir. For Gensyn, it uses verifiers to re-run portions of generated proofs to check against proofs while whistleblowers act as another layer of check on verifiers. Meanwhile, Aethir uses checker nodes to determine service quality, giving penalties for subpar service. Render proposed to use a dispute resolution process, slashing the node should the review committee find the node at fault. Phala generates a TEE proof upon completion, ensuring AI agents execute the required actions on-chain.
Hardware Statistics
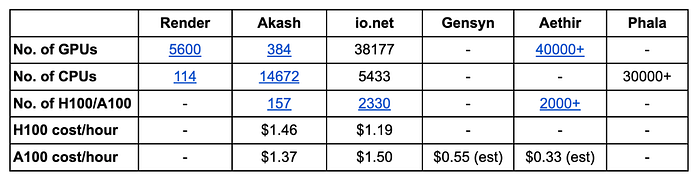
Requirement for High-Performance GPUs
Since AI model training requires the best performance GPUs, they tend towards GPUs such as Nvidia’s A100 and H100 which offer the best quality even though the latter can fetch a high price on the market. Looking at how A100 was able to not just train all workloads but do so at a faster rate, it only goes to show how much the market values such hardware. With the H100 having a much higher inference performance that is 4 times faster than the A100, it has now been the go-to GPU especially for large corporations that are all training their own LLM.
For decentralized GPU marketplace providers to compete with their Web2 counterparts, it has to offer not just lower rates but to serve the actual demand in the market. Nvidia in 2023 delivered more than half a million H100s to centralized big tech companies, making it expensive and difficult to acquire as much equivalent hardware to compete with large cloud providers. Thus, looking at the amount of hardware these projects can bring onto their network at low cost is important to scale these services to larger groups of customers.
Although every project has a business in AI and ML compute provision, they differ in their capabilities to provide for compute. Akash only has a total of over 150 units of H100 and A100, compared to io.net and Aethir who managed to acquire over 2000+ units each. Generally, pretraining an LLM or generative model from scratch requires at least 248 to over 2000 GPUs in a cluster, making the latter 2 projects more desirable for large model compute.
Depending on the cluster size required from such developers, the current cost available in these decentralized GPU services in the market is already at a much higher discount compared to its centralized counterpart. Gensyn and Aethir both boast being able to rent A100 equivalent hardware at less than $1 per hour, but this still needs to be proven over time..
Having a high number of GPUs with low hourly cost, an issue of network connected GPU clusters is that they are memory bound compared to NVLink-ed GPUs. NVLink enables direct communication between multiple GPUs, removing the need for data transfers between CPUs and GPUs to achieve high bandwidth with low latency. Compared to network connected GPUs, NVLink connected GPUs are best suited for LLMS with many parameters and large datasets since they require high-performance and intensive computations.
Despite this, decentralized GPU networks still offer substantial compute power and scalability for distributed computing tasks for those who have dynamic workload requirements or require the flexibility and ability to distribute workloads across multiple nodes. By offering a more cost-efficient alternative to centralized cloud or data providers, these networks open up the oligopoly for building more AI and ML use cases compared to centralized AI models.
Provision of Consumer Grade GPU/CPUs
Although GPUs are the main processing units required for rendering and compute, CPUs play a part in training AI models as well. CPUs can be used in several parts of training including data preprocessing all the way to memory resource management, which can come in useful for developers in developing their model. Consumer-grade GPUs can also be used for less intensive tasks such as fine tuning an already pre-trained model or training smaller-scale models on smaller datasets at a more affordable cost.
Although projects like Gensyn and Aethir primarily focus on enterprise-grade GPUs, other projects such as Render, Akash, and io.net can also serve this portion of the market given that over 85% of consumer GPU resources sit idle. Providing these options can allow them to develop their own niche in the market, allowing them to focus on high-scale intensive compute to more general purpose smaller scale rendering or a mix in between.
Conclusion
The AI DePIN sector is still relatively new and faces its own challenges. Their solutions have been criticized for their feasibility and have encountered setbacks. For instance, io.net was accused of falsifying GPU numbers on their network, an issue later resolved by introducing a Proof-of-Work process to verify devices and prevent sybils.
Despite this, there has been a notable rise in jobs performed and hardware onboarded into these decentralized GPU networks. The increasing volume of tasks performed on these networks underscores a rising demand for alternatives to Web2 cloud providers for hardware resources. Concurrently, the proliferation of hardware providers within these networks highlights a previously underutilized supply. This trend further demonstrates AI DePIN networks’ product market fit, as they effectively address challenges from both demand and supply.
Looking ahead, the trajectory of AI points toward a burgeoning multi-trillion dollar market and we think these decentralized GPU networks are poised to play a pivotal role in providing cost-effective compute alternatives for developers. By continuously bridging the gap in demand and supply through their networks, these networks are set to contribute significantly to the future landscape of artificial intelligence and computing infrastructure.
About DFG
Digital Finance Group (DFG) is a leading global Web3 investment and venture firm, established in 2015. With assets under management exceeding $1 billion, DFG’s investments span across diverse sectors within the blockchain ecosystem. Our portfolio boasts investments in pioneering projects such as Circle, Ledger, Coinlist, FV Bank, ChainSafe, Polkadot, Solana, Render, and over 100 others.
At DFG, we are committed to generating value for our portfolio companies through market research, strategic consult, and sharing of our vast resources globally. We are actively working with the most transformative and promising blockchain and Web 3.0 projects poised to revolutionize the industry.
DFG Website: https://dfg.group
DFG Twitter: @DFG__Official
DFG LinkedIn: DFG
